k均值聚类算法代码
- 算法
- 2024-07-18 11:33:46
- 3005
1、 是的。 传统上,对于符合要求的内素检测,最终用户必须从标准内素库存瓶中构建至少一式两份三点标准曲线;必须有重复的阴性控;每个样品和PPC必须一式两份。 有了Sievers Eclipse内素检测仪,这些步骤可以通过使用预嵌入的内素标准品实现自动化,这些内素标准品包括5点标准曲线和预嵌入的PPC。 因此,用户所需要做的就是将细菌内素检测用水和样品置入平板,而不需要额外的准备工作。 其结果是实验设置仅需9分钟,而其他平台需要60分钟以上。
4、 K-MEANS算法的终止条件可以是以下任何一个:1、没有(或最小数目)对象重新分配给不同的聚类。 2、没有(或最小数目)聚类中心再发生变化。 3、误差平方和部最小。 伪代码 选择k个点作为初始质心。 repeat 将每个点指派到最近的质心,形成k个簇,重新计算每个簇的质心,until,质心不发生变化。

3、 在聚类分析中,K-均值聚类算法(k-means algorithm)是无监督分类中的一种基本方法,其也称为C-均值算法,其基本思想是:通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
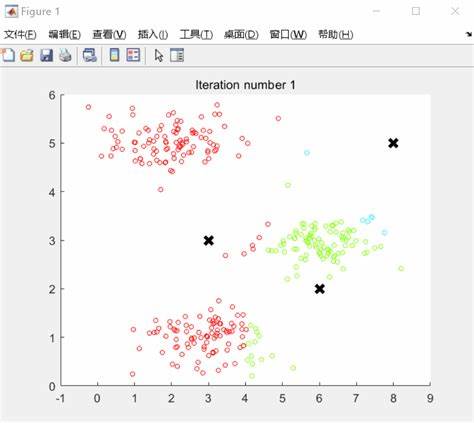
2、 算法的时间复杂度上界为O(n*k*t), 其中k为输入的聚类个数,n为数据量,t为迭代次数。

5、 K-均值聚类 K-means聚类算法采用的是将N*P的矩阵X划分为K个类,使得所有类内对象与该类中心点之间的距离和最小。










热门文章
fanuc程序传输步骤
2024-07-18 11:02:00
微信有哪些搞笑小程序
2024-07-18 11:01:31
备份mysql数据库
2024-07-18 11:00:35
写代码的程序员怎么样
2024-07-18 10:59:31
必胜客小程序点餐
2024-07-18 10:58:43
程有哪些实际用途呢
2024-07-18 10:57:40
怎么把微信小程序的链接变成网址
2024-07-18 10:57:25
程序的循环代码是什么
2024-07-18 10:56:43
智慧消防和消防物联网
2024-07-18 10:56:36
数据结构概念包括三个方面
2024-07-15 09:45:51