k-means算法流程图
- 算法
- 2024-09-08 09:12:08
- 5823
基本的k-means算法流程如下:选取k个初始质心(作为初始cluster) repeat:对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的clusterk-means工作流程创建k 个点作为起始质心(通常是随机选择)当任意一个点的簇分配结果发生改变时(不改变时算法结束)对数据集中的每个数据点对每个
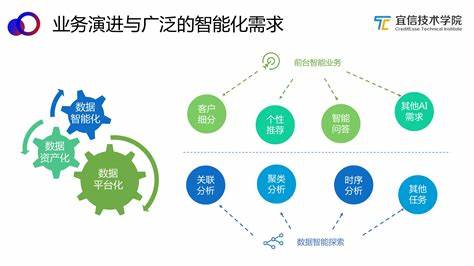
K-means算法是一种基于划分的聚类方法,其流程如下: 1. 初始化:选择K个初始聚类中心。2. 分配:将每个样本点分配到最近的聚类中心所代表的簇中。3. 更新:重新计算每个簇的平均值,并将其作为新的聚类中心。4. 判断:如果聚类中心不再发生变化,或者达到预设的最大迭代次数,则停止迭代;否则,返回第2步。5. 输出:输出每个样本点所属的簇以及每个簇的中心。K-Means算法,也称K-均值,是一种使用广泛的最基础的聚类算法。K-means算法流程图,可供参考使用~
数字图像处理入门第66节:用小例子讲解k-means算法流程及如何实现。实验中对彩色图像的色彩值进行了聚类,用3种颜色表征了图像的全部内容,从实验结一、K-means算法主要过程(1)从数据中选择k个对象作为初始聚类中心;(2)计算每个聚类对象到聚类中心的距离来划分;(3)再次计算每个聚类中心
上一篇:物联网用哪三种架构









热门文章

怎么将抖音小程序游戏全部删除
2024-09-08 09:10:46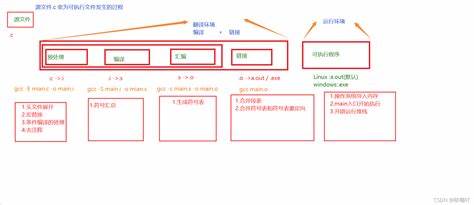
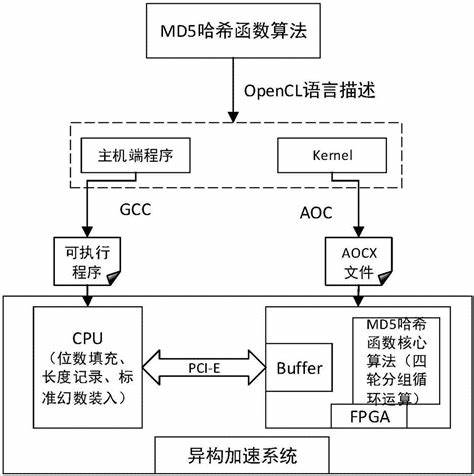
vs怎么由源代码变为程序
2024-09-08 09:10:19
access数据库数据类型英文
2024-09-08 09:10:35
算法技巧归纳
2024-09-08 09:10:33
程序员必备八股文pdf
2024-09-08 09:10:26
数据库主键和外键能是同一个吗
2024-09-08 09:10:27
最好的区块链的股票
2024-09-08 09:10:09
如何才能成为一个顶级的程序员
2022-06-19 17:57:07
数据库的数据类型主要分为几种
2024-09-08 09:10:05
自家店做外卖小程序要多少钱
2024-09-08 09:10:01